1 引擎由来
1.1 起因
- 产品需求更改频繁
- 经常新增, 去除业务功能
- 核心业务逻辑变动频繁, 最终逻辑无人知晓
下面是一次产品业务逻辑的PRD文档
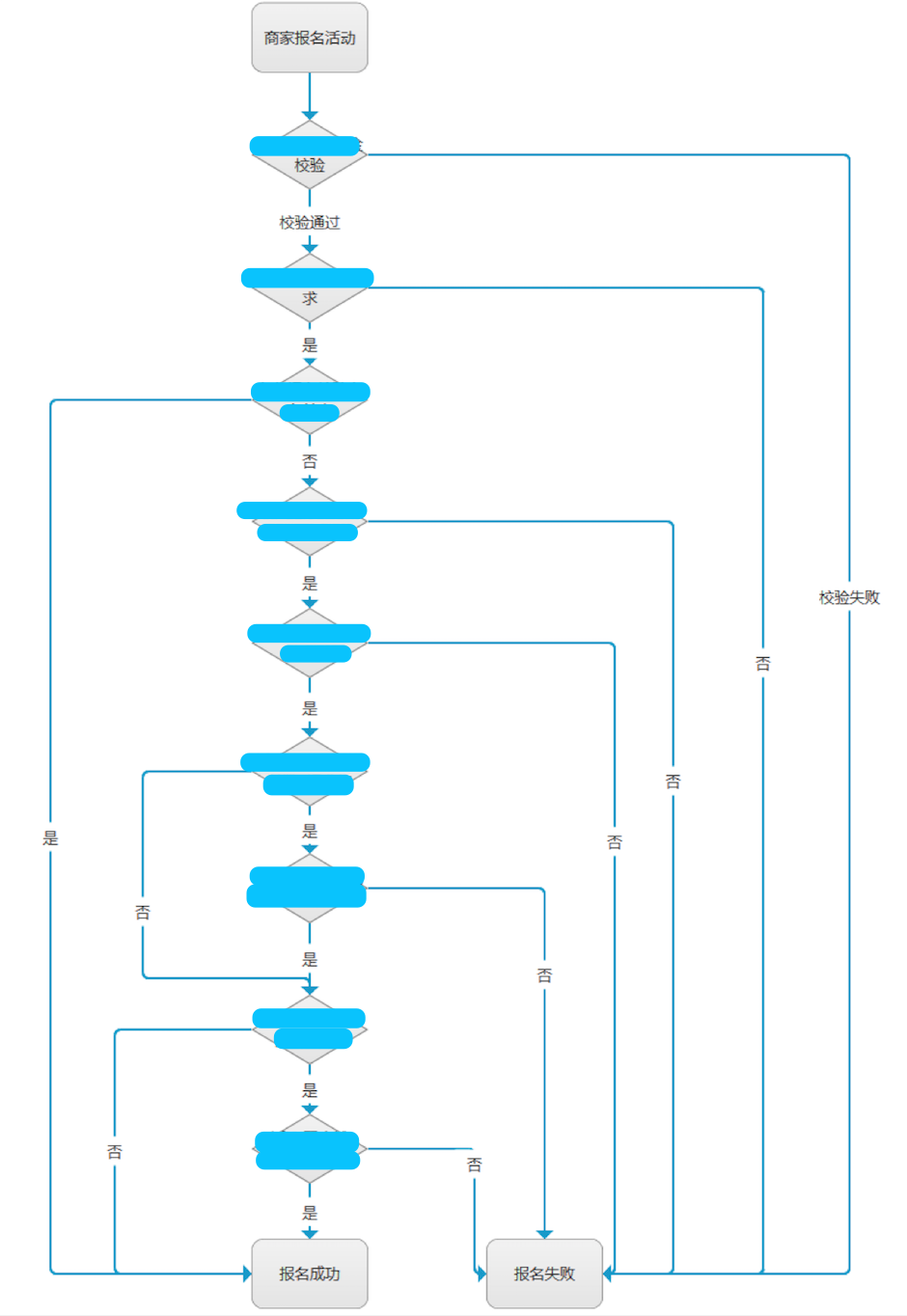
上述逻辑非常复杂, 每一个分支又有自己独立的逻辑, 再经过几次需求的变动, 最终报名的逻辑无人知晓, 只能通过研发去从代码中找逻辑, 出现的bug也很难排查.
基于上述痛点, 我们研发了业务流引擎, 它主要解决下面几个问题
- 流程配置可视化, 流程图即是代码
- 每一个流程的执行过程可视化
该引擎的设计参考了 Netflix的微服务编排工具Conductor 和 美团的从0到1:构建强大且易用的规则引擎
1.2 引擎配置
下面是我们业务流引擎系统的一个的配置图:
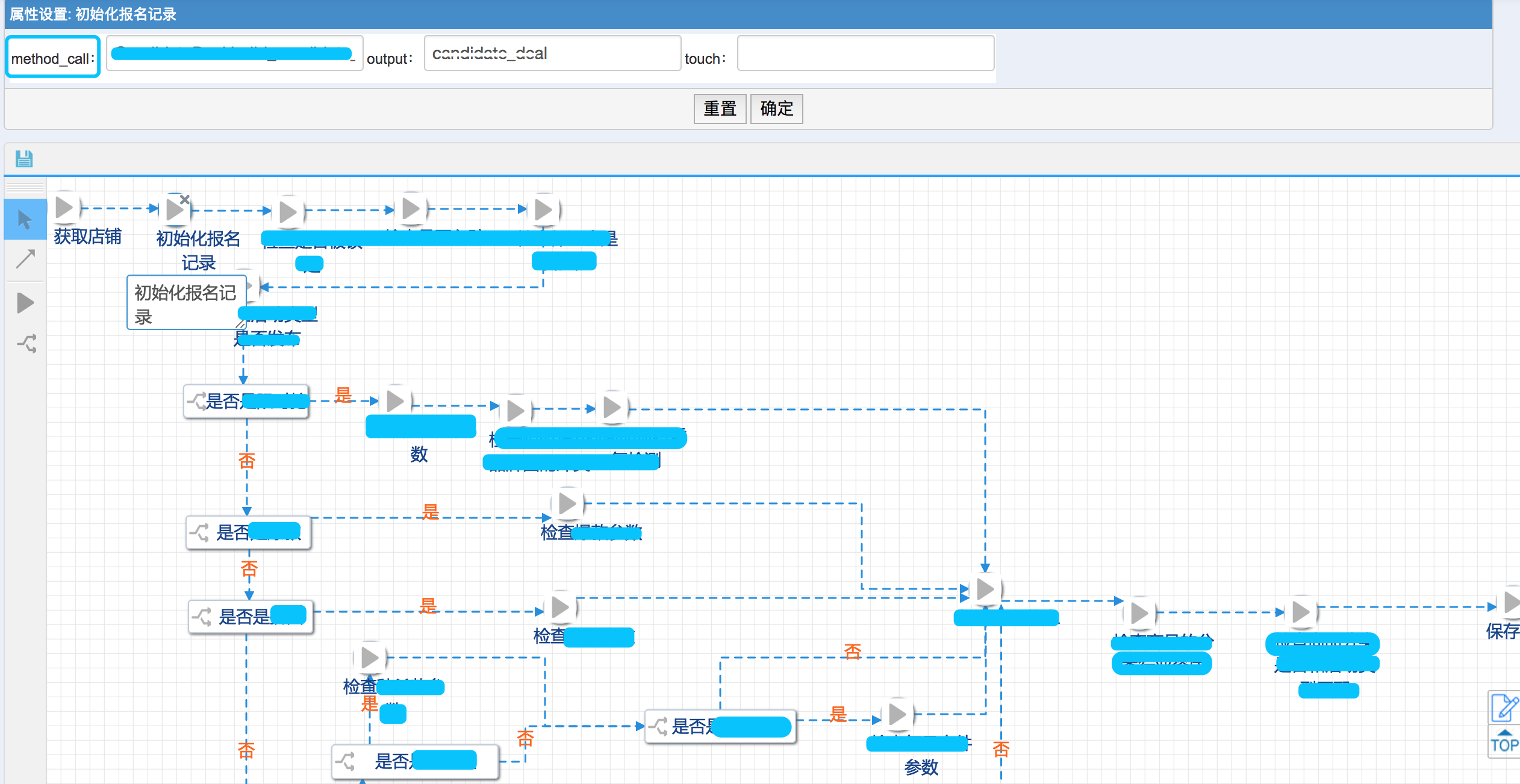
每一个配置项都包括下面几个参数
| 字段 | 释义 |
|---|---|
| method_call | 方法调用函数 |
| output | 输出参数 |
| touch | 是否支持重试 |
由上图可以看到: 我们将一个复杂的业务流强制拆解为一个一个的方法,
并将方法通过拖拽的形式进行组装, 形成一个完整的业务流程.
1.3 原有报名逻辑重构
原有报名逻辑如下:
42 ##
43 # ==== Description
44 # 创建报名记录
45 #
49 def create_candidate_deal(params_hash)
50 logger.info("传入参数: #{params_hash} at: #{Time.now.to_s(:db)}")
51
52 candidate_deal = ::CandidateDeal.new
53 candidate_deal.assign_attributes(params_hash['candidate_deal'])
...
211
212 if candidate_deal.zhe_trade?
213 ProductClient.submit(current_shop, [candidate_deal.product_id])
214 end
215
216 logger.info("传入参数: #{params_hash} 报名流程结束")
217 end
我们可以看到, 代码从42行一直到217, create_candidate_deal 这个方法做了很多事情, 因为流程的复杂,
很容易产生 Fat Method, 各种 If Else 嵌套逻辑, 代码变得难以测难和维护.
1.3.1 流程引擎改造
-
配置流程图名称
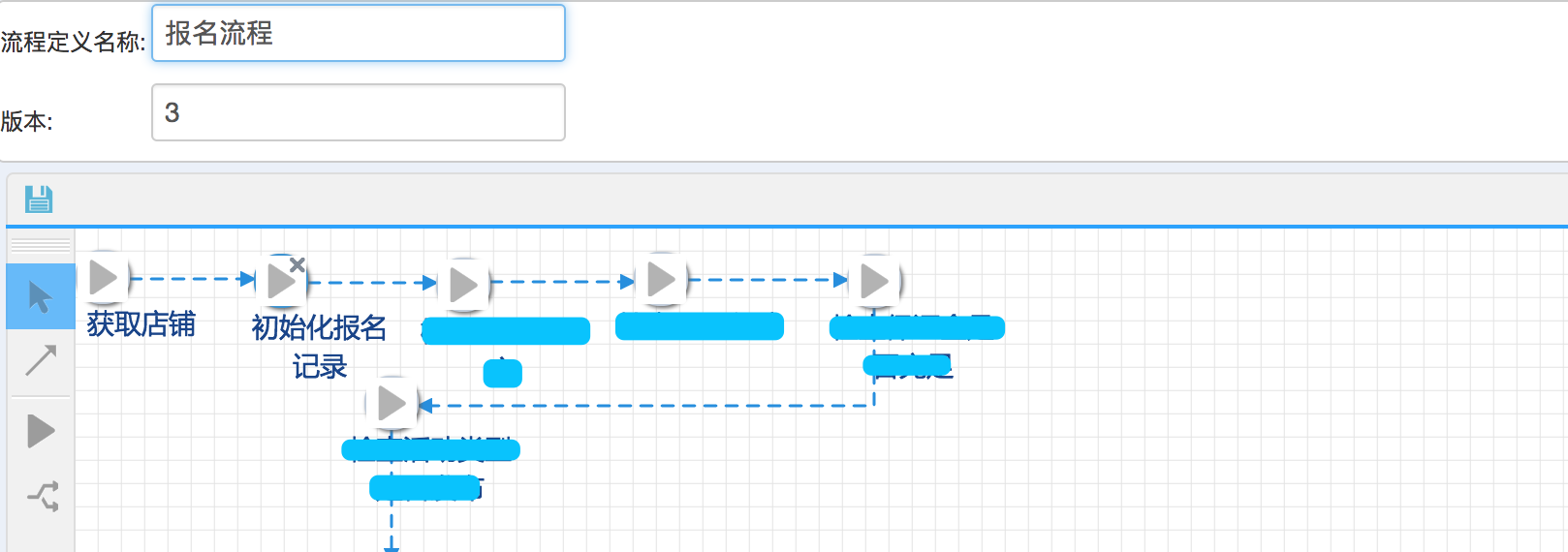
如上图所示, 整个流程配置了两个字段
name: 报名流程 version: 3
这两个字段确定了一个唯一的业务流程图.
-
引擎接管逻辑运行
通过配置流程名称和版本号
name: "报名流程", version: 3, 即可获取到整个流程配置.原有的复杂的一百多行报名逻辑的代码可以简化为不到10行的代码:
def create_candidate_deal_by_witness(params_hash) witness = { name: "报名流程", version: 3 }, # 配置 流程名称 和 版本号 runner = ::Witness::Ast::Runner.new( witness: witness, params: params_hash ) result = runner.run # 执行run方法, 即可运行整个流程图 if result[:status] == :error raise result[:message].to_s end end
1.4 执行结果可视化
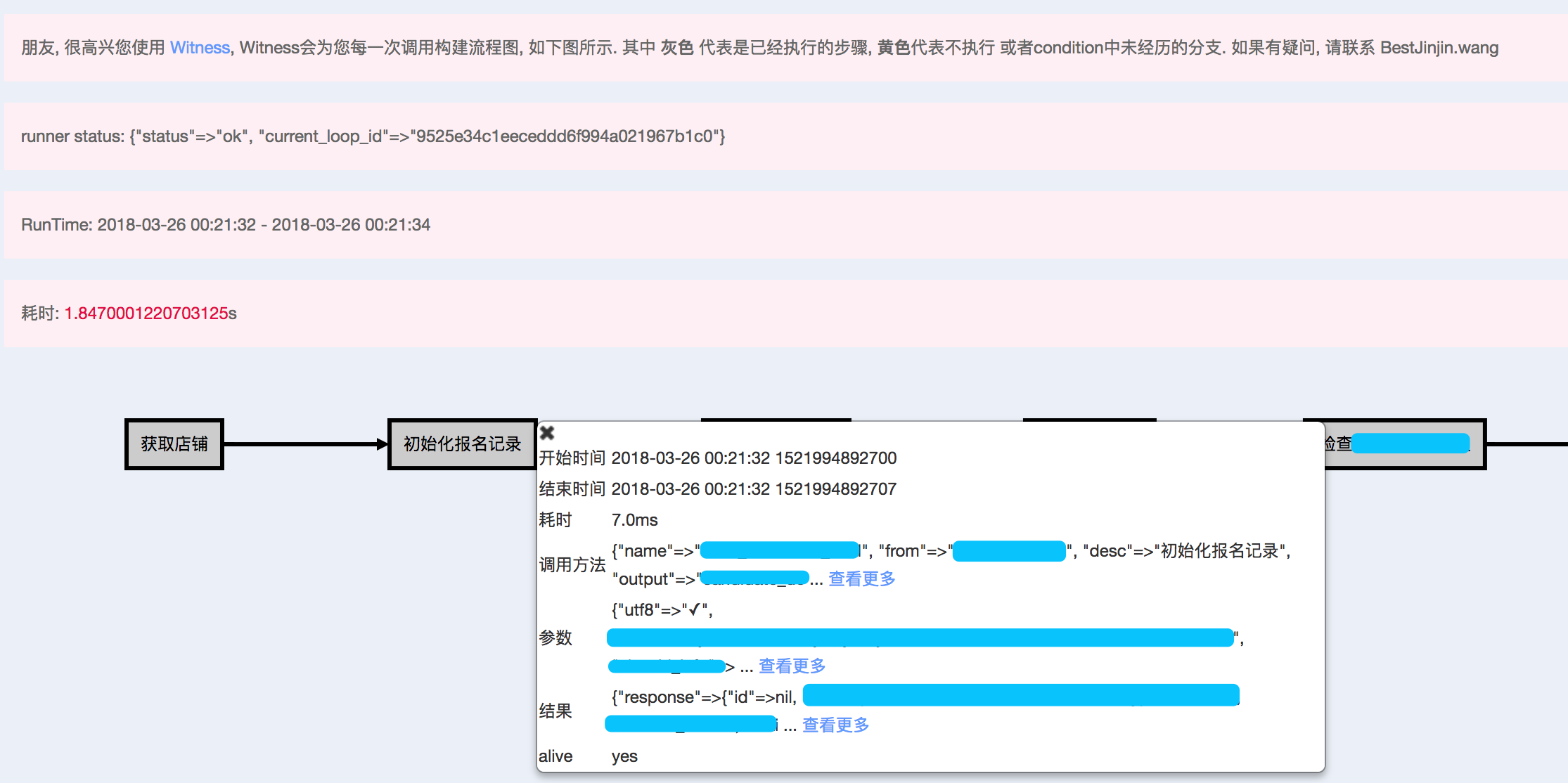
从上图可以看到, 每一个运行步骤都是可视化的, 包括下面这些参数
- 开始执行时间
- 结束执行时间
- 调用方法体
- 参数
- 返回结果
从上面的参数可以很方便得看到每一次流程运行的整个过程
1.4.1 可视化产生的性能问题
-
时间维度的性能问题
由于所有的信息都是推送到
kafka异步处理的, 推送消息的时间基本稳定在1ms左右, 最复杂的业务流大概包括20个步骤, 故性能的损耗大概为20ms, 该部分的时间对于整个报名系统而言, 影响基本可以忽略不计. -
存储空间问题
由于记录了每一次运行的结果, 为了更好地扩展参数, 我们将整个上下文都存储到了
ES, 会占用非常大的存储空间, 经过估算后, 我们仅保留一周的数据. 1周之前的数据将进行定时删除.
2 架构设计
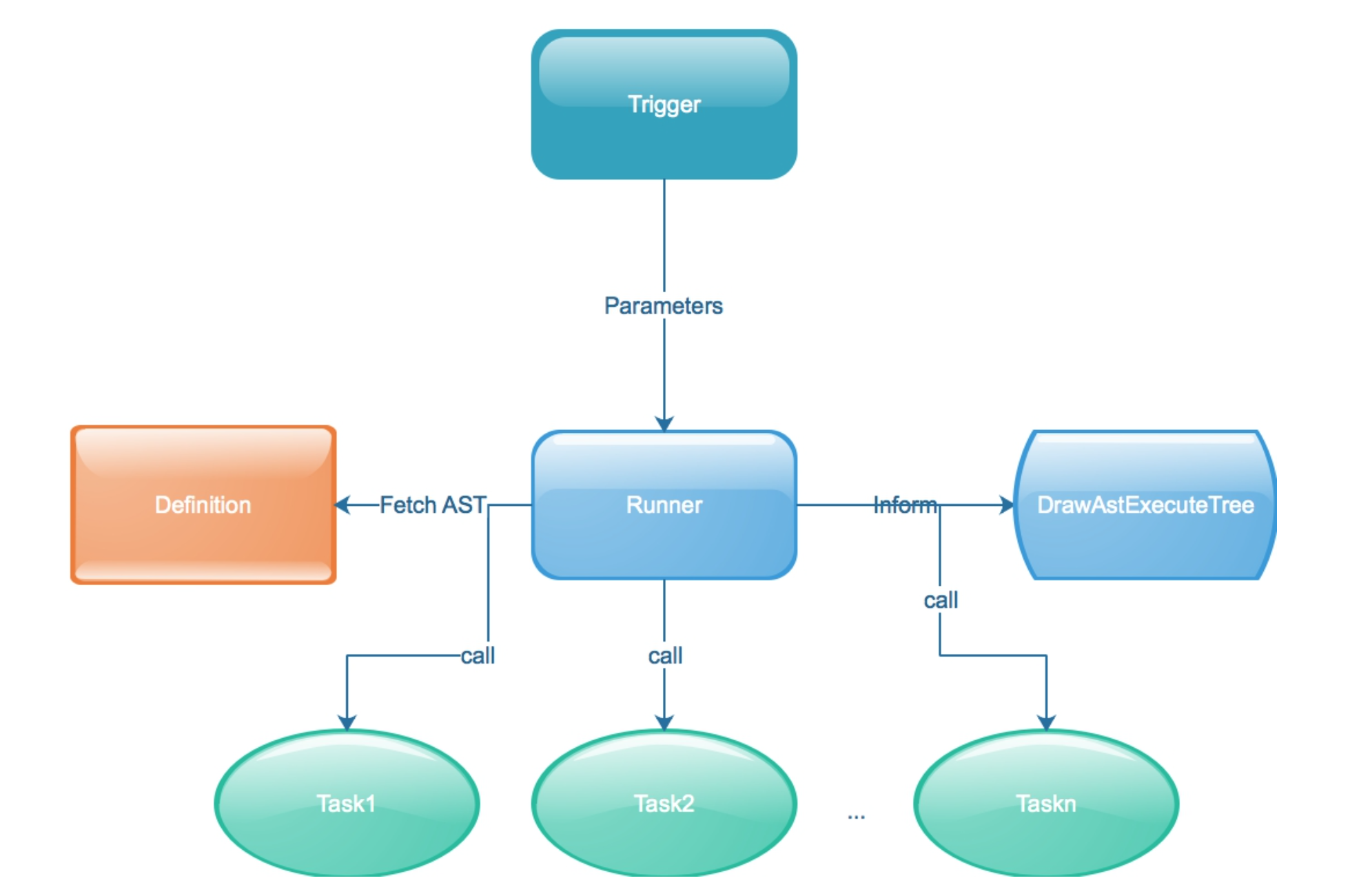
2.1 Runner
执行引擎, 该部分接收流程图配置信息和对应的参数, 负责执行业务流程图的代码.
runner = Witness::Ast::Runner.new(witness: Witness::Zhaoshang::Example, params: {})
runner.run
2.2 AST Definition
生成一个执行树, 包含了整个流程图的信息
Witness::Ast::Node.new(definition)
2.3 Vistor
通过Vistor对执行树进行遍历
该部分参考了Rails源码中Arel的设计, 按照深度优先的方式遍历AST树, 每一个Vistor都有不同的作用实体,
分别执行不同的任务.
项目中用到的Visitor如下:
| VistorType | 释义 |
|---|---|
| CallVisitor | 执行引擎 |
| MethodValidationVisitor | 方法合法性校验引擎 |
| SVGGeneratorVisitor | SVG生成器,生成最终的可视化流程图 |
2.4 Inform
所有的流程执行上下文都推入了 Kafka 队列, 最终数据落地至 ElasticSearch.
3 优缺点分析
3.1 优点
- 业务流更加清晰, 任何人都可以对业务流引擎进行修改和维护
- 强制将现在的
Fat Method变为Tiny Method, 更容易进行单元测试和黑盒测试 - 可以提前进行架构设计, 书写伪代码
3.2 缺点
- 和传统的写代码的思维方式不同
- 方法的调用是在数据库中的, 会出现很多方法在项目中找不到调用的地方
- 业务流过于复杂之后, 编排本身变成一个耗时的事情
