1 Sidekiq基本框架
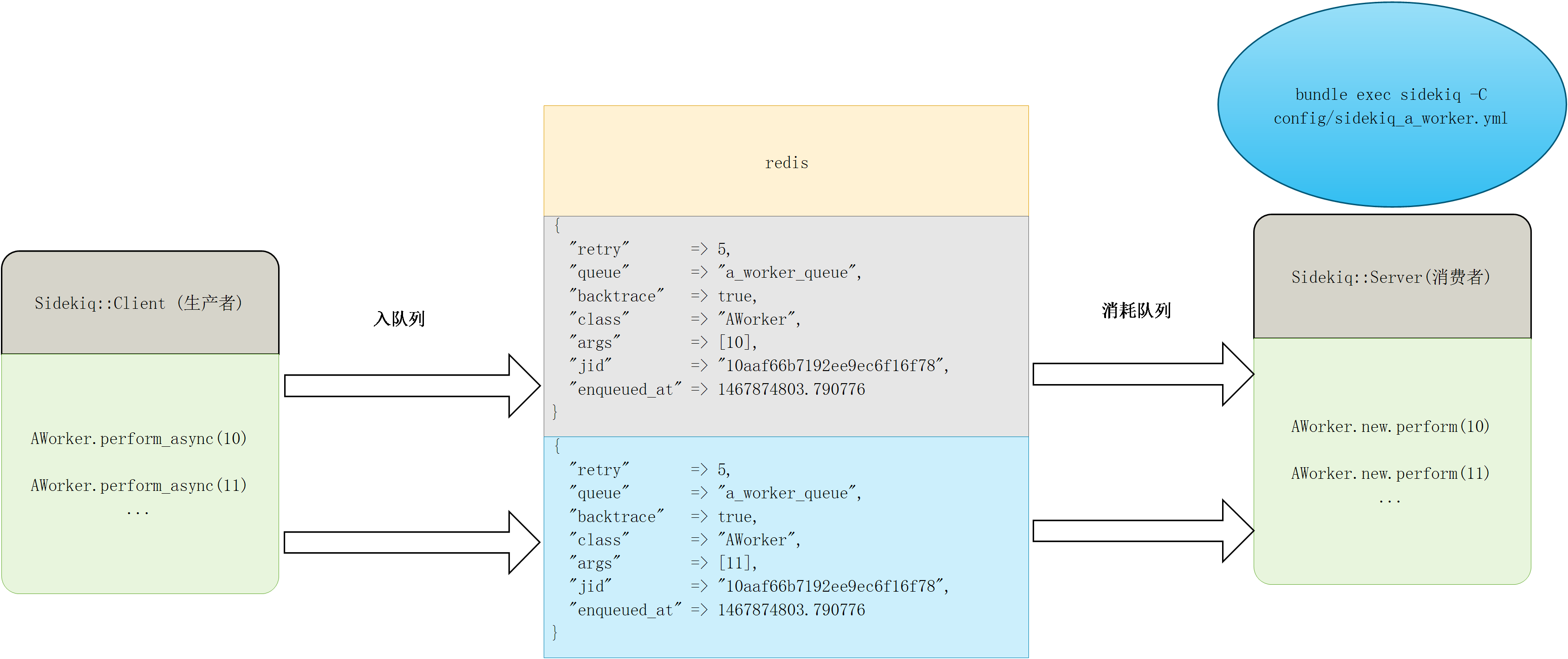
Sidekiq基于Redis作为存储, 一个例子如下:
2 Sidekiq Client
Sidekiq Client部分为队列数据的生产者, 在 Sidekiq 源码中可以看到
module Sidekiq
class Client
def push(item)
normed = normalize_item(item)
payload = process_single(item['class'.freeze], normed)
if payload
raw_push([payload])
payload['jid'.freeze]
end
end
def atomic_push(conn, payloads)
q = payloads.first['queue'.freeze]
now = Time.now.to_f
to_push = payloads.map do |entry|
entry['enqueued_at'.freeze] = now
Sidekiq.dump_json(entry)
end
conn.sadd('queues'.freeze, q)
conn.lpush("queue:#{q}", to_push)
end
end
end
最终会在Redis中存储下面这些信息
- retry 重试次数
- queue 队列名称
- backtrace 错误栈
- class 处理类名称
- args 参数
- jid job_id
- enqueued_at 进入队列的时间
并将这些信息通过lpush存储在Redis的队列中.
3 Sidekiq Server
3.1 Before 4.0
Sidekiq4.0之前, 使用的是Celluloid作为多线程的抽象层
模型如下:
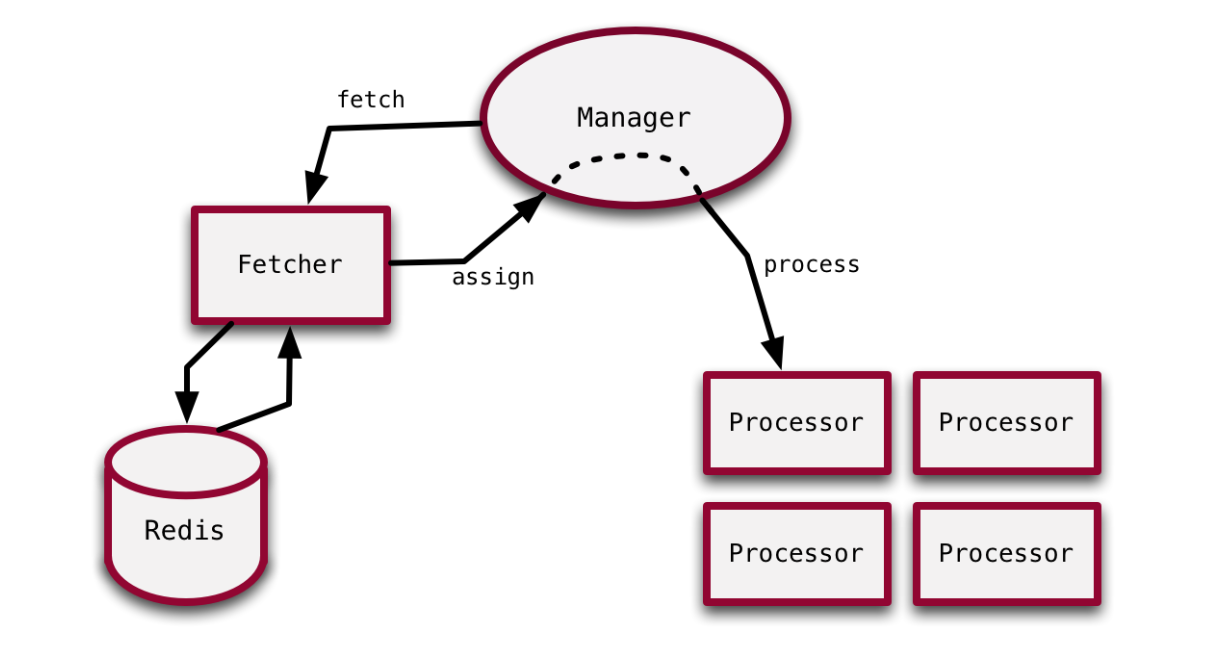
源码分析请参考 Working With Ruby Threads-Chapter 15
3.2 After 4.0
在4.0版本之后, Sidekiq出于性能考虑, 使用原生的Thread实现了一个简易的Actor版本模型. 相关文章请见这里 和 这里
模型如下:
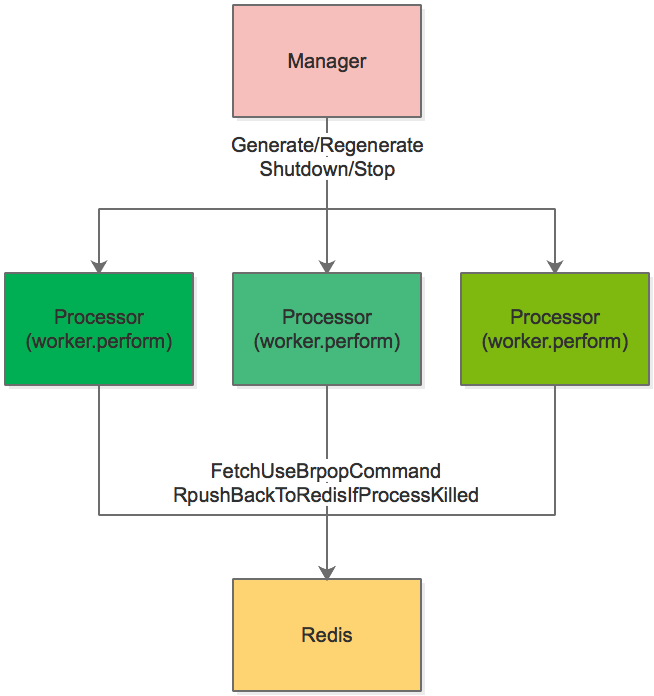
核心的组件包括
-
Manager
Manager根据用户设置的并发数, 生成处理队列任务的Processor, 并对idle或者dead的Processsor进行管理, 包括:1. start: Spin up Processors. 2. processor_died: Handle job failure, throw away Processor, create new one. 3. quiet: shutdown idle Processors. 4. stop: hard stop the Processors by deadline.
初始化Manager
class Manager def initialize(options={}) logger.debug { options.inspect } @options = options @count = options[:concurrency] || 25 raise ArgumentError, "Concurrency of #{@count} is not supported" if @count < 1 # @done代表是否结束处理任务 @done = false @workers = Set.new # 生成多个Processor, 每一个Processor对象在被调用start方法的时候, 会生成了一个线程 @count.times do @workers << Processor.new(self) end # 添加一个锁, 用于修改 @workers 的数据, 管理Processor对象 @plock = Mutex.new end end启动Manager, 即调用
Processor#startclass Manager def start @workers.each do |x| x.start end end end -
Processor
Processor是处理任务的类, 包括下面的功能1. fetches a job from Redis using brpop 2. executes the job a. instantiate the Worker b. run the middleware chain c. call #perform
Processor#start, 启动Processor, 创建一个线程class Processor def start # 生成一个线程, 并调用run方法 @thread ||= safe_thread("processor", &method(:run)) end endProcessor#run, 处理任务, 去Redis获取队列数据# @mgr 即为他对应的 Manager 对象 class Processor def run begin while !@done # 调用 perform 方法进行处理 process_one end # 一旦结束了, 则将 Processor对象中的manager对应的worker去掉, 即是改变了上述 Manager的 @workers 数组 @mgr.processor_stopped(self) rescue Sidekiq::Shutdown # 在接收到TERM SIGNAL之后, 等待超时的时候sidekiq会抛出异常 Sidekiq::Shutdown, 见下文分析 # 线程被关闭. @mgr.processor_stopped(self) rescue Exception => ex # 程序报错了, Manager#processor_died 会重新生成一个新的Processor线程 @mgr.processor_died(self, ex) end end end
3.3 队列重启时job的处理
当我们更新代码后, 需要重启Sidekiq的进程. 一般来说, 我们会发送一个 TERM SIGNAL 指令给Sidekiq进程, 它的执行步骤如下
-
停止Fetch jobs.
class Manager def quiet return if @done # 将 @done 设置为 true @done = true logger.info { "Terminating quiet workers" } @workers.each { |x| x.terminate } # 这里的每一个 x 都是一个Processor对象 fire_event(:quiet, reverse: true) end end class Processsor def terminate(wait=false) @done = true # 将每一个Processor 的 @done 设置为 true, 下面的run方法则不再fetch新的job return if !@thread @thread.value if wait end def run begin while !@done process_one end # 一旦结束了, 则将 Processor对象中的manager对应的worker去掉, 即是改变了上述 Manager的 @workers 数组 @mgr.processor_stopped(self) rescue Sidekiq::Shutdown @mgr.processor_stopped(self) rescue Exception => ex @mgr.processor_died(self, ex) end end -
等待
Sidekiq.options[:timeout]秒(默认为8秒)的时间, 使得Processor去处理完当前未完成的jobsclass Manager def stop(deadline) quiet fire_event(:shutdown, reverse: true) # some of the shutdown events can be async, # we don't have any way to know when they're done but # give them a little time to take effect sleep PAUSE_TIME return if @workers.empty? logger.info { "Pausing to allow workers to finish..." } remaining = deadline - Time.now # 等待默认的8s后, 如果 @workers 为空, 则代表在规定时间内任务都处理完, 退出 while remaining > PAUSE_TIME return if @workers.empty? sleep PAUSE_TIME remaining = deadline - Time.now end return if @workers.empty? # 等待默认的8s后, 如果 @workers 不为空, 则进行强制shutdown hard_shutdown end end -
如果在等待时间之后, 仍存在正在处理的job, 则将job通过rpush命令推入Redis, 强制使 processor 退出
class Manager def hard_shutdown # We've reached the timeout and we still have busy workers. # They must die but their jobs shall live on. cleanup = nil @plock.synchronize do cleanup = @workers.dup end if cleanup.size > 0 # 获取没有处理完的job jobs = cleanup.map {|p| p.job }.compact logger.warn { "Terminating #{cleanup.size} busy worker threads" } logger.warn { "Work still in progress #{jobs.inspect}" } # Re-enqueue unfinished jobs # NOTE: You may notice that we may push a job back to redis before # the worker thread is terminated. This is ok because Sidekiq's # contract says that jobs are run AT LEAST once. Process termination # is delayed until we're certain the jobs are back in Redis because # it is worse to lose a job than to run it twice. strategy = (@options[:fetch] || Sidekiq::BasicFetch) # 将未处理完的jobs推入队列的头部 strategy.bulk_requeue(jobs, @options) end # 强制kill掉线程 cleanup.each do |processor| processor.kill end end end class Processor def kill(wait=false) @done = true return if !@thread # unlike the other actors, terminate does not wait # for the thread to finish because we don't know how # long the job will take to finish. Instead we # provide a `kill` method to call after the shutdown # timeout passes. @thread.raise ::Sidekiq::Shutdown @thread.value if wait end end
注意在接收到TERM SIGNAL一些job有可能被重复执行. Sidekiq的FAQ中有说明: Remember that Sidekiq will run your jobs AT LEAST once.
Sidekiq 还提供了 Scheduling Job 的功能, 即到时执行任务, 该部分使用了一个 SortedSet 的redis数据结构, 排序的因子为任务的执行时间. 在启动 Sidekiq 服务的时候, 会启动了一个线程轮询所有执行时间小于等于当前时间的队列数据, 将该部分的数据在pop至队列, 再由 Processor 处理.
4 Sidekiq Middleware
Sidekiq 在 client-side 和 server-side 都支持AOP操作, 该部分和Rack的原理一致.
有了server-side middleware的支持, 我们可以
在sidekiq处理任务前后, 捕捉到任务的处理情况
如Sidekiq提供了 ActiveRecord 的 server-side middleware
module Sidekiq
module Middleware
module Server
class ActiveRecord
def initialize
# With Rails 5+ we must use the Reloader **always**.
# The reloader handles code loading and db connection management.
if defined?(::Rails) && ::Rails::VERSION::MAJOR >= 5
raise ArgumentError, "Rails 5 no longer needs or uses the ActiveRecord middleware."
end
end
def call(*args)
yield
ensure
::ActiveRecord::Base.clear_active_connections!
end
end
end
end
end
对于基于Rails的Sidekiq服务, Sidekiq会确保在每次执行任务之后, 都会清掉使用的连接, 避免多线程占用过多的Rails数据库连接.
5 AsyncTask
5.1 需求分析
我们经常有一些这样的需求:
1. 给卖家批量报名活动, 一次可以报名200个商品, 如果报名失败的记录, 需要有提示信息 2. 批量创建活动, 一次导入一个1万条商品的excel, 需要给这1万条数据创建 3. 批量导出50万大促信息
最开始我们都是通过串行的方式进行处理, 比如
1. 给卖家批量报名活动, 一次可以报名200个商品, 如果报名失败的记录, 需要有提示信息
我们提供一个商品的HTTP接口, 然后由JS发Ajax请求进行调用, 但是该方式有一些问题:
- 数据容易丢失
- 一些接口请求很慢, 容易造成超时
- JS交互复杂, 大量的逻辑都放在了前端, 出问题不好排查
但是对于数据量大的情况, 串行调用变得非常慢, 如
2. 批量创建活动, 一次导入一个1万条商品的excel, 需要给这1万条数据创建 3. 批量导出50万大促信息
我们考虑使用Sidekiq进行处理, 即每一个任务都放在Redis里面. 调用perform_async方法, 获取到任务的job_id
job_id = ProductWorker.perform_async(params)
但是新的问题出现了: 我们无法获取到这个job的完成情况, 如果逻辑上处理失败, 也无法获取到对应的错误信息.
Sidekiq-Pro 支持batches功能, 但是它是收费的.
我们最终决定利用 Sidekiq 的 Middleware 特性, 研发出一套异步任务管理引擎, 它支持
- 任务的聚合管理. 一个task和多个job进行关联
- 可以获得job的执行状态
- 所有执行过程可视化
5.2 AsyncTask
任务处理引擎架构图
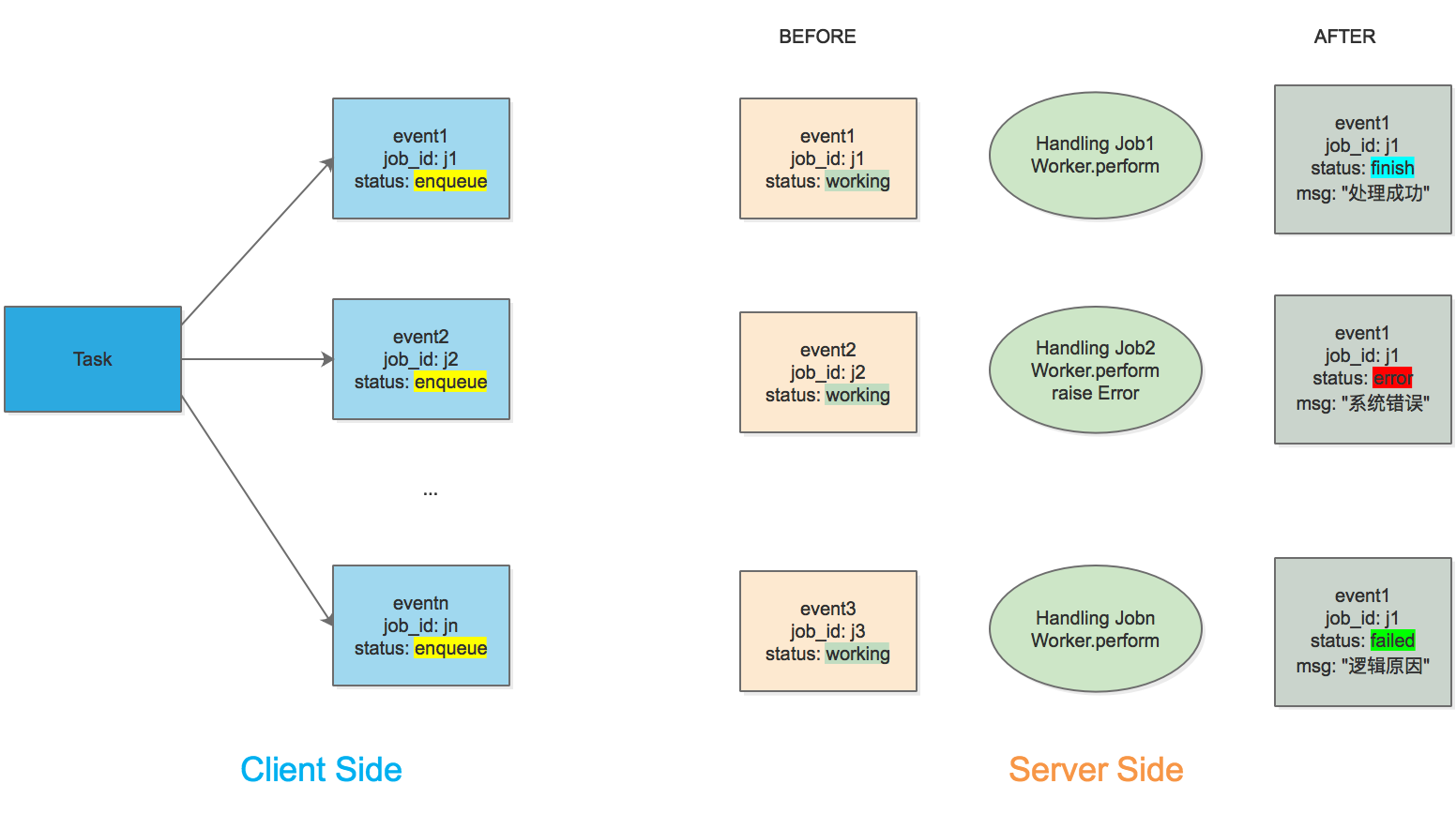
它包含三部分
- 创建Task, 生成task_id, 将每一个任务都推入Redis, 并获取到对应的job_id
- 生成Event记录, 该Event和job_id一一对应, 记录了整个job的生命周期
- 利用Server-Side Middleware, 记录Event的状态和相关信息
步骤一的job_id由Sidekiq生成
5.2.1 Task 和 Event 创建
我们将Task和Event都创建了对应的数据库表, 则
class Task has_many :events end class Event validates_uniqueness_of :job_id belongs_to :task end
Task的数据结构为
| 字段 | 释义 |
|---|---|
| worker_name | worker的名称 |
| id | 主键id |
Event的数据结构为
| 字段 | 释义 |
|---|---|
| job_id | 任务id,全局唯一 |
| status | 当前状态,包括enqueue,working, finish, failed, error
|
| params | 任务执行的所有参数 |
| added_messages | 增量的信息,记录整个任务的流程 |
注意到status包含了 falied 和 error 两个不同的状态. 其中 failed 代表为 业务逻辑上的失败, 如一个卖家因为资质不合格导致无法报名, 为了获取该状态, 处理时可直接抛出异常(NormalException), 状态为failed. 而 error 代表为系统错误, 如程序bug或者接口超时等
5.2.2 Server-Side Middleware
在这里我们配置了 use_task_event, 如果需要使用该插件, 需要在 worker 中配置 use_task_event: true.
class AWorker
include Sidekiq::Worker
sidekiq_options use_task_event: true
def perform(options)
handle_job(options)
end
end
Server-Side Middleware代码和注释如下:
module AsyncTask
class MiddlewareServer
def call(worker, item, queue)
if item['use_task_event'] # 配置入口
begin
job_id = item['jid']
Task.record(job_id, :working, message: "处理中")
yield
# 正常处理成功, 设置 status 为 finish
Task.record(job_id, :finish, message: "已经完成")
rescue SystemExit, Interrupt => ex
# 被中断, 设置 status 为 error
Task.record(job_id, :error, message: "被中断")
# 如果之后会被重试, 则重新再设置为 :enqueue
if retry_status.is_a?(Integer) && (retry_status > 0) && retry_count &&
(retry_status - 1 != retry_count.to_i)
Task.record(job_id, :enqueue, message: "等待重试")
end
raise ex
rescue NormalException => ex
# 业务逻辑上的失败, 设置 status 为 failed, 错误信息放在 message 中
Task.record(job_id, :failed, message: "发生错误: #{ex.message}")
rescue Exception => ex
# 程序bug, 设置 status 为 error
Task.record(job_id, :error, message: "发生致命错误: #{ex.message}")
# 如果之后会被重试, 则重新再设置为 :enqueue
if retry_status.is_a?(Integer) && (retry_status > 0) && retry_count &&
(retry_status - 1 != retry_count.to_i)
Task.record(job_id, :enqueue, message: "等待重试")
end
raise ex
end
else
yield
end
end
end
end
在项目启动时加载该Middleware
Sidekiq.configure_server do |config|
config.server_middleware do |chain|
chain.add AsyncTask::MiddlewareServer
end
end
5.3 问题剖析
回顾在文章开始时提到的需求
1. 给卖家批量报名, 一次可以报名200个商品, 进行活动, 如果报名失败的记录, 需要有提示信息 2. 批量创建活动, 一次导入一个1万条商品的excel, 需要给这1万条数据创建 3. 批量导出50万大促信息
对于需求1, 2, 都可以用相同的处理方式, 流程如下:
- 前端一次将所有的数据全部提到给后端.
- 后端根据数据量拆分为n个jobs, 并生成一个task_id, 返回给前端.
- 前端每隔一段时间, 调用后端的接口来询问 task_id 对于的 job 的状态, 如果出错, 则一同返回错误信息.
对于需求3, 我们可以将50万信息分为不同的worker来处理, 并用统一的task_id进行关联, 也将大大提高导出的效率.
