1 Overview
- Leader Election
- Log Replication
- Safety
1.1 Replicated state machine architecture
分布式数据一致性算法的一个经典的架构为 Replication state machine, 即
- 记录多个日志(Replicated Log)
- 维护了一个最终状态的状态机(State Machine).
任何一台服务器挂掉或者无法进行通信时, 新的服务器可通过日志进行数据的回溯和重算. 得到当前的最终的状态, 并代替原有服务器, 和client进行通信
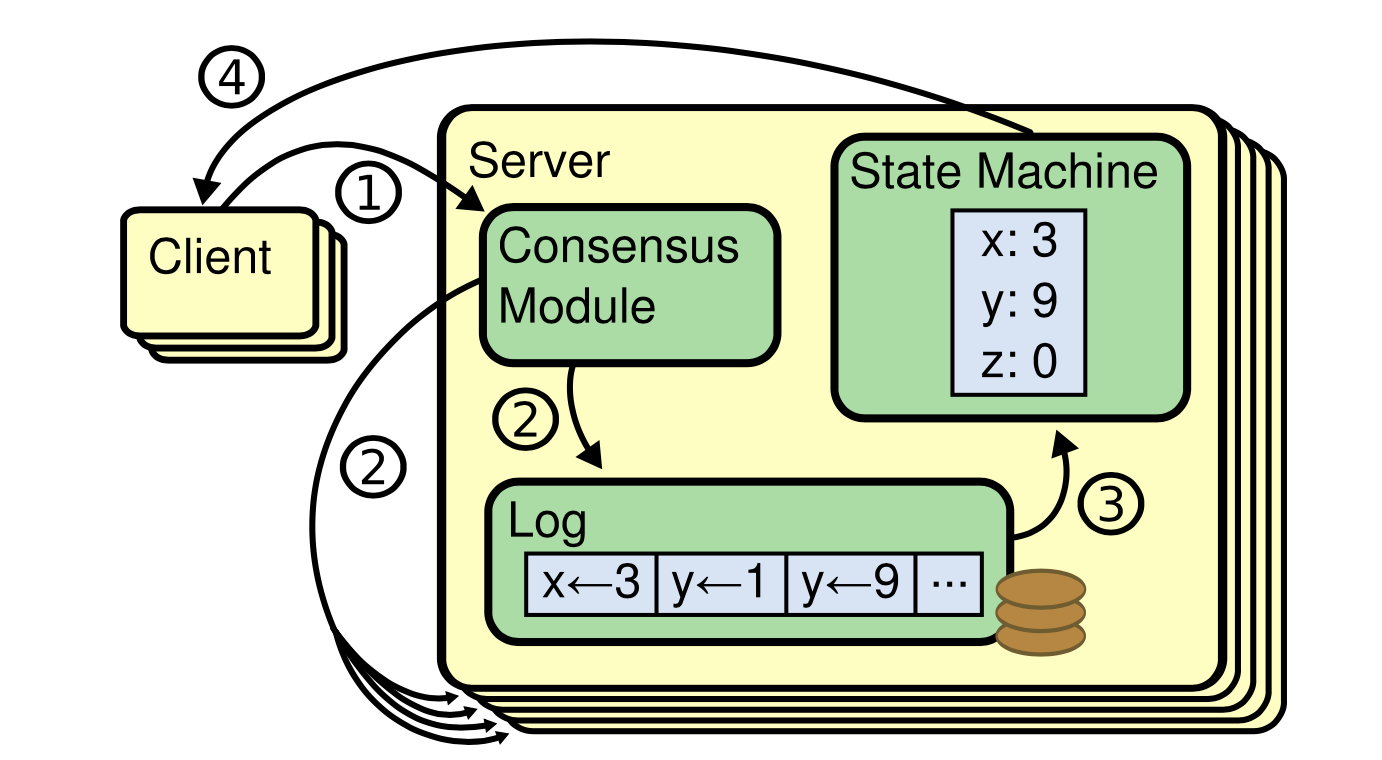
Client 和 Server 通信的时候(上图中的步骤1), Server端会写log, 其中log记录的是 数据的变化过程, 并同步到多个机器中(步骤2), 存在一个状态机, 状态机保存的是数据的最终结果(步骤3), 状态机计算完结果之后, 将结果返回给Client通信成功(步骤4)
论文原文摘录:
Keeping the replicated log consistent is the job of the consensus algorithm. The consensus module on a server receives commands from clients and adds them to its log. It communicates with the consensus modules on other servers to ensure that every log eventually contains the same requests in the same order, even if some servers fail. Once commands are properly replicated, each server’s state machine processes them in log order, and the outputs are returned to clients. As a result, the servers appear to form a single, highly reliable state machine.
在Kafka的高可用策略中, 也采用了相应的策略: Leader先写日志, 在成功同步到半数以上的Follower之后, 才返回给客户端ack.
1.2 Key Concepts
核心的概念如下:
-
Leader
用于和Client交互的载体
-
Term
时间序列编号(Terms act as a logical clock in Raft), 每一次Election之后, term 会递增.
在做心跳的时候, term信息是一直传输的
Raft divides time into terms of arbitrary length. Terms are numbered with consecutive integers, and each term begins with an election.
-
Log Entries
用于记录 commands, 即所有的操作
1.3 Consensus Problems to Subproblems
Raft算法将 一致性问题 拆分成了 三个子问题: leader election, log replicated 和 safety
1.3.1 Leader Election Problem
Leader挂了, 将重新进行election, 选出新的Leader
选取的时候会查看 被选取的candidate的时间序列term和对应的log Index 和 自身的对比.
仅仅当
candidate's term > voter's term || (candidate's term == voter's term && candidate's latestLogIndex >= voter's latestLogIndex )
这个candidate才能得到voter的赞成票.
选举的规则非常重要, 这个规则和commited的概念一起, 解决了后面safety问题
1.3.2 Log Replication Problem
Leader接收到消息之后, 需要写入log, 并将这些log同步到大多数的Follower 去, Follower 返回ack 之后, Leader 才返回给Client ack.
1.3.3 Safety Problem
- Election restriction
- Leader, Follower, Candidate crashed
2 Leader Election
2.1 Status
Raft算法每一个节点都有三个状态, 也可以认为是三种身份:
- Follower
- Candidate
- Leader
所有的交互都是跟 Leader 进行, 变化会写入 Leader 的log, 再进行 Log Replication, 采用的方式为 Append Entries.
状态变化如下图:
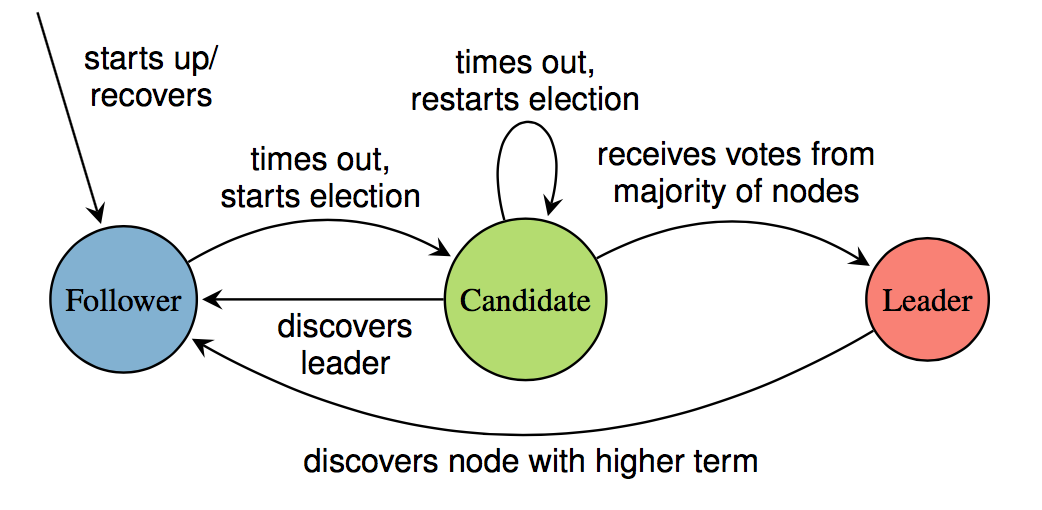
大型的分布式系统都会有一个 replicated state machine
Large-scale systems that have a single cluster leader, such as GFS, HDFS, and RAMCloud, typically use a separate replicated state machine to manage leader election and store configuration information that must survive leader crashes. Examples of replicated state machines include Chubby and ZooKeeper.
2.2 Flow
Raft采用心跳 Heartbeat mechanism 来触发Election.
Leader会周期性地给Follower 发送心跳, 一旦Follower接收不到消息, 则会重新进行Election
2.3 超时问题
一个Candidate进行Election可能会出现下面三种情况
- 成功
- 失败, 其他的Candidate变成了Leader
- 超时, 在一定时间内没有收到投票
如果超时了, 会再次进行选取, 此时如果有多个Follower变成了Candidate(Split), 则 有可能谁都不会胜利, 拿不到大多数的投票, 此时会变回Follower, 并进行随机时间区间(150ms-300ms)的等待 (randomized election timeouts), 再进行下一步的leader选取.
由于等待了随机的时间, 再次Split的概率就会很小.
3 Log Replication
3.1 Overview
leader_write_log # 写日志(不提交) leader_send_replicate # 复制节点, 发送给follower leader_get_majority_of_followers_ack # 获得大多数的follower的确认写入 leader_commit # leader 提交(Committed)
If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries.
3.2 检测不一致的方式
Leader写入的log形式如下:
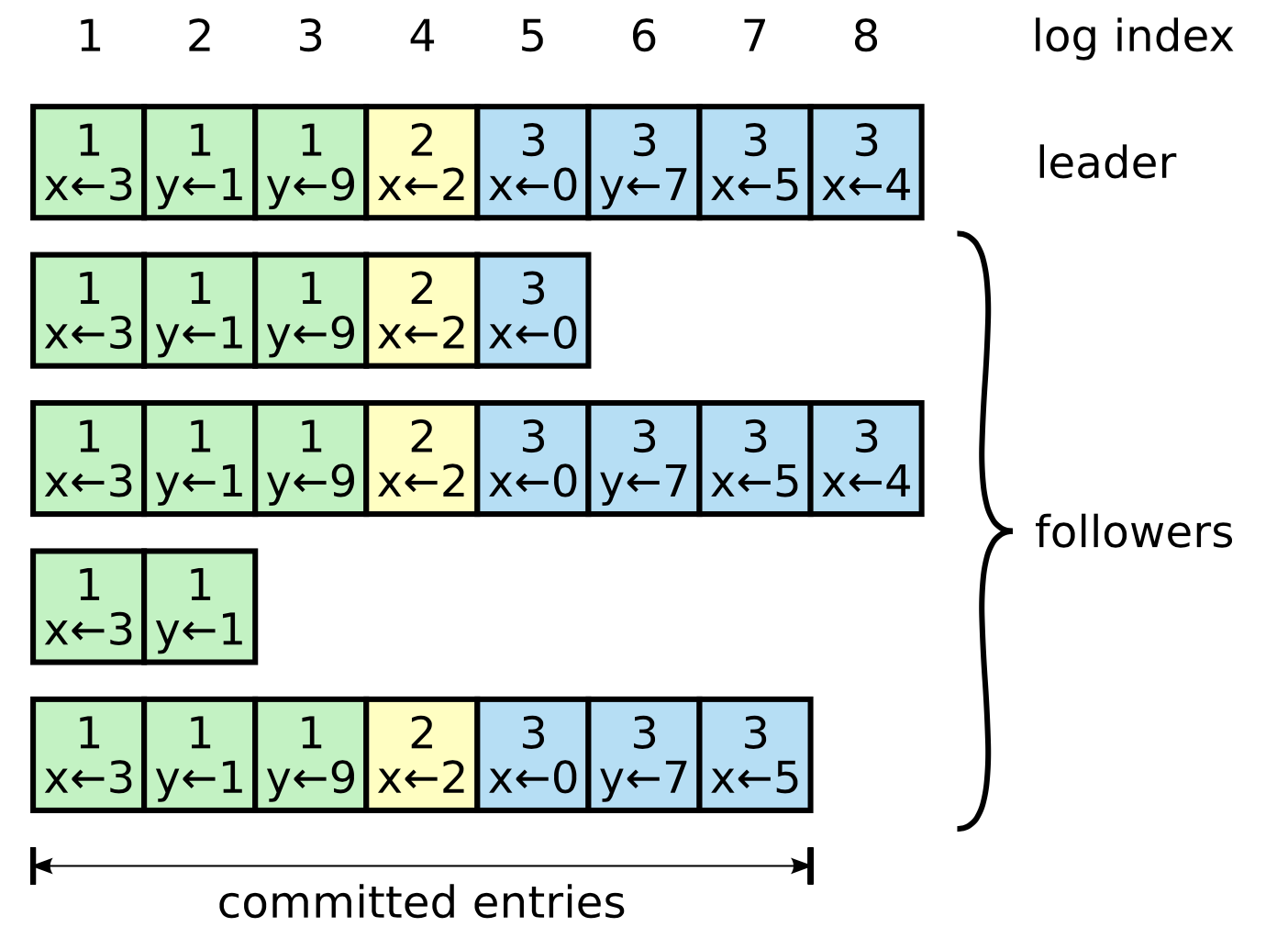
其中不同的颜色, 代表不同的term.
通过term值和log的最大的index, Leader可以知道Follower的Log Entries是否已经追上或者是落后. 如果发现落后了, 则在下次心跳的时候, 再将数据进行同步.
如果Follower超前了, Follower会将他的数据删除, 保持logEntries和Leader的一致.
3.3 Committed
论文原文摘录:
A log entry is committed once the leader that created the entry has replicated it on a majority of the servers (e.g., entry 7). This also commits all preceding entries in the leader’s log, including entries created by previous leaders
一旦 term 和 maxIndex 是一致的, 则最终的结果就是一致的, 存储的命令也是一致的
可以证明, 所有已经commited 的 entry, 在所有的机器上是一致的.
4 Cluster Memeber Changed
这一部分讨论的问题是 如何扩容 的问题
4.1 Joint Consensus
这部分不是很理解
5 Client Interaction
客户端会随机向某一台服务器发送请求, 如果服务器不是leader的话, 它会拒绝这个请求并 告知最新的leader的地址
