1 TL;DR
角标的计算使用了 视图 + SQL 的数据计算引擎概念.
如现在需要表达一个角标, 满足这个角标条件的SQL为:
SELECT * FROM deals
WHERE
isHongPiPiWuyou = 1
AND
isSingleOnSale = 1
AND
isZhuanchangPromoted = 1
AND
isTodayNew = 1
计算引擎将上述SQL进行了分析, 分析过程为:
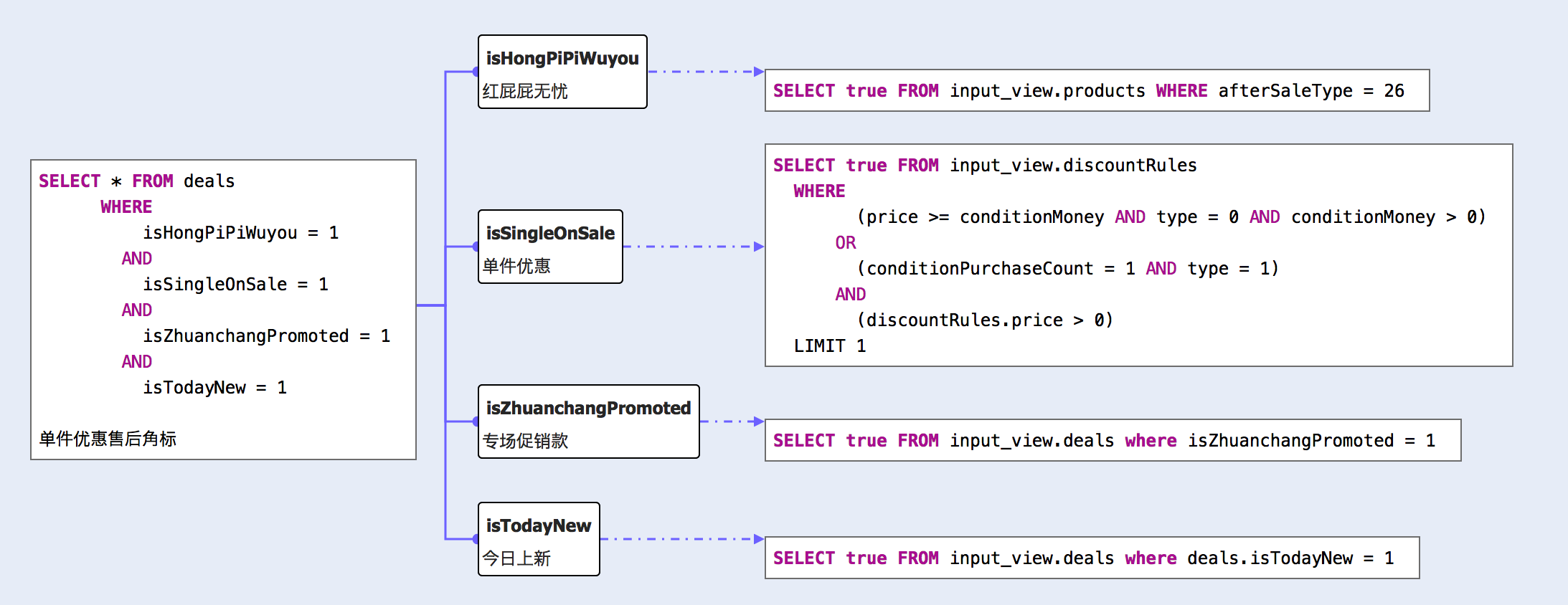
通过一层一层的视图建立和计算, 我们将复杂的问题变成了 视图数据准备 + SQL表达逻辑 这两个部分,
将逻辑表达和数据准备进行解耦, 从而可以通过简单的配置和组合, 实现复杂的业务逻辑.
该思路理论上可以用于任何复杂的业务系统, 实现前端数据层和后端数据层的解耦, 表示层和数据层解耦
2 角标的整体设计
2.1 角标基本属性
角标作用于一个展示的坑位, 在坑位的不同位置展示角标的文字或者图片信息
坑位: 指一个商品的展示位置
角标有下面这些属性
- 开始时间
- 结束时间
- 角标文案信息(如示例中的 "即将恢复至49.9")
- 角标图片信息(如示例中左上角的图标 "限时特价")
如下图所示, 页面中 限时特价 和 即将恢复至49.9元 即为一个完整的角标
![]()
2.2 角标作用实体
角标的作用实体为一个坑位, 这个坑位里面可以是
- 商品
- 一张图片
- 一个聚合形式的商品(如特卖活动等)
2.3 角标基础模型
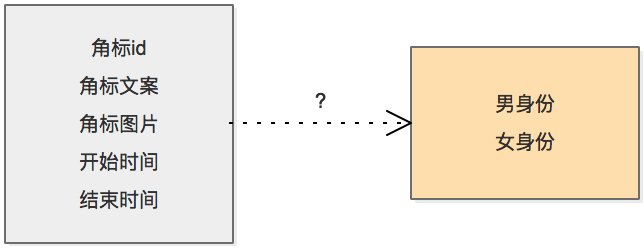
什么样的坑位能命中角标? 可以考虑用id来配置角标, 即建立坑位id 和角标的关联关系
![]()
2.4 角标需求范围扩展
上述设计为最初的角标设计模型, 只是一个简单的 坑位id 和 角标id的对应关系, 通过该关系来进行配置.
慢慢随着业务地增长, 角标变得复杂起来. 主要包括下面的需求:
-
要求在某个特定client展示
我有一个活动, 这个活动为了将PC端的用户引流到APP端, 所以我要求在PC打一个特殊的标, 这个标不在APP展示

-
要求在某个页面中展示
我有一个秒杀的活动, 这个活动有可能在APP的任何地方展示, 但是我这个角标, 只能在APP的秒杀列表页展示, 其他的地方不展示

-
要求不同用户身份打不同的标
我有一个拉新客的活动, 这个活动只给新用户展示, 不给老用户展示

-
要求不同用户角色打不同的标
3月8日, 我想搞一个女神活动, 希望一些标只对 女性 用户展示
-
要求通过店铺id进行批量打标
我有一个店铺, 这个店铺很不错, 我想给这个店铺下所有的活动都打上一个 "好商家" 的角标, 我不希望用 商品id 来设置角标, 而是希望用店铺id来配置

-
特殊规则打标
我希望对全网所有商品中, 库存小于100的商品都打上一个标: "库存告急, 仅剩XXX件" 我希望所有满足"一个商品就可以商品优惠"的商品, 打上一个 "促销价XXX元"的标, 全网适用 我希望...

2.4.1 黑暗时代
虽然出现了上述需求, 当时角标系统还是坚持着简单的 坑位id 和 角标id的对应关系 的方式, 仅保存角标的基本属性, 所以出现了下面的情况
- 一个简单地添加角标需求, 需要 PC端, APP端, 角标后台设置, 数据服务端同时进行更改.
- 角标展示逻辑都是以文字形式提出, 很多角标命中逻辑纷繁复杂, 很多逻辑都是硬编码在各个业务代码中
- 为了满足按照 "店铺id, 大促id" 等聚合id打标, 实现了大量地定时任务, 将店铺id/大促id下的所有的活动都创建了一条对应(坑位-角标)关系记录
- 角标设置混乱, 容易导致重叠, 出了问题之后很难排查, 不同的需求方来投诉角标不对的问题, 应该展示的角标没展示或者展示错误, 由于角标逻辑分散, 问题很难排查
2.5 问题分析
-
角标规则问题
角标的主要问题在于, 未将 "规则" 纳入到角标的体系中, 需要让规则可以配置, 这样才可以约束规则, 变得更加规范
-
角标服务
将角标系统的逻辑收敛, 所有角标系统需要参数都需要传入, 统一提供接口
-
角标需要有优先级
给角标的规则设置上权重, 当一个商品命中多个角标的时候, 可以选择权重最高的角标
最终的角标设计如下:
![]()
3 角标特殊规则设计
角标的基础规则包括:
- 客户端类型 client_type, 如 PC, APP
- 命中的页面 page_lists, 如 "秒杀页面, 男装分类页面"
- 新老用户 user_type, 如新老用户
- 用户角色 user_role, 如 男用户, 女用户 等
上述的规则可以通过枚举值, 提前存储在表中. 但是特殊规则怎么办?
3.1 特殊规则示例
我们先看看一下一些例子
- 我想给 所有 "参加秒杀活动的商品" 添加一个角标
- 我想给 "分类 等于 男装 而且 尺码 > XXL的商品" 添加一个角标
- 我想给 "库存 > 0 而且 < 10 的商品" 添加一个角标
- 我想给 所有 "是单件优惠的商品" 添加一个角标
根据下面的这些情况, 我们总结如下
- 特殊规则由
条件组成, 通过 "AND" 和 "OR" 的关系进行组合 - 条件包括下面几种类型
- 是否 (是否是秒杀, 是否是单件优惠)
- 输入 (分类 == ?)
- 区间 (如库存 BETWEEN (0, 10))
考虑一个非常复杂的例子:
我想要打一个超级男装单件优惠标, 标的定义如下: (商品是秒杀 而且 分类是男装) 或者 (商品为单件优惠 而且 剩余库存 在 10 到 20 之间)
可以设计为下面的形式:
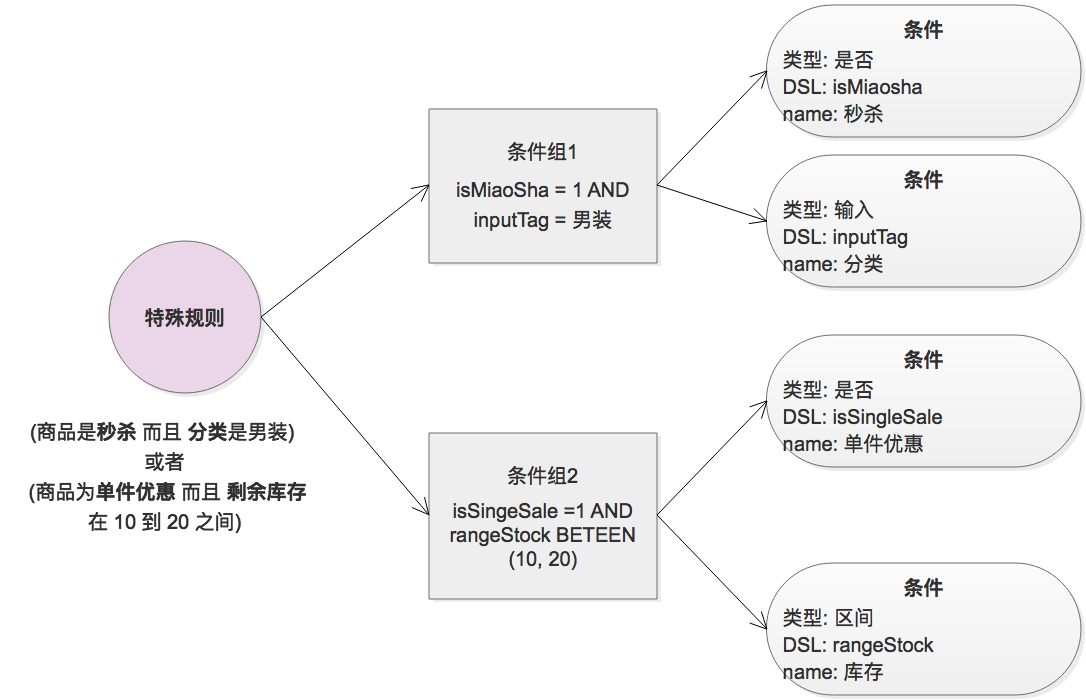
3.2 角标条件
从上面的设计形式, 可以看到, 最原子化的数据为 条件, 条件和条件之间, 由条件组进行关系组装
3.2.1 条件
她的属性包括:
- type: 是否/输入/区间
- DSL: 对于程序段可以识别的字符串, 如 isMiaosha, 在程序段将有一个映射表, 后续会讲到该字段
- name: 标识条件的具体含义
3.2.2 条件组
条件组 包含 多个条件, 条件组中的条件为 AND 的关系
3.3 特殊规则设计
- 特殊规则 由 多个 条件组 关联
- 条件组 由 多个角标条件 构成
- 条件包含三个类型: 是否/输入/区间
- 条件DSL为一个算法约定, 在之后计算角标时使用, 该算法可以重用
添加了特殊角标规则之后的设计图如下:
![]()
4 角标计算
数据结构 + 算法 = 程序。结构是本质,故数据结构决定算法。如果一个语言即能无缝的表示数据,又能表示算法,该多棒! LISP 和 SQL就是, LISP是因为其高度自由的表达,即:语法 和语义解耦; SQL即表示数据计算、数据本身、又表示数据的迁移、存储、数据的访问, 是高度的抽象,是命令式的语言。 ---- 亚历山大 K Liu
4.1 内存数据库
4.1.1 什么是内存数据库
内存数据库是指构造bean数组, 将这些数组认为是表, 再将数据聚合变成一个数据库. 我们可以通过SQL对该数据库进行查询
下面是一个内存数据库的例子, 源码在这里
现有 products 和 sellers 两张表, 她们通过 products.sellerId 和 sellers.id 进行关联. 对应的数据模型为
public class SqlRunnerTest {
// 使用一个Database对象来存储这些数据
public static class Database {
public Seller[] sellers;
public Product[] products;
}
public static class Seller {
public String name;
public int id;
public Seller(String name, int id) {
this.name = name;
this.id = id;
}
}
public static class Product {
public int id, sellerId;
public Product(int id, int sellerId) {
this.id = id;
this.sellerId = sellerId;
}
}
}
构造数据如下:
public class SqlRunnerTest {
static Database database;
static SqlRunner sqlRunner;
static String sql;
@BeforeClass public static void setUp() {
Seller[] sellers = {
new Seller("dengqinghua", 1),
new Seller("kimiGao", 2),
new Seller("DS", 3),
};
Product[] products = {
new Product(1024, 1),
new Product(1025, 2),
new Product(1026, 3),
};
database = new Database();
database.products = products;
database.sellers = sellers;
}
}
测试用例如下:
public class SqlRunnerTest {
static Database database;
static SqlRunner sqlRunner;
static String sql;
@Test public void run() throws Exception {
sqlRunner = new SqlRunner("merchant_system", database);
sql = "SELECT \n"
+ "\"products\".\"id\", \"sellers\".\"name\" \n"
+ "FROM \n"
+ " \"merchant_system\".\"products\" \n"
+ "INNER JOIN \n"
+ " \"merchant_system\".\"sellers\" \n"
+ "ON \n"
+ " \"merchant_system\".\"sellers\".\"id\" = \"merchant_system\".\"products\".\"sellerId\" \n"
+ "WHERE \n"
+ " \"sellers\".\"name\" = 'dengqinghua'";
Result<Record> result = sqlRunner.run(sql);
assertThat(result.format(), is(
"+----+-----------+" + "\n" +
"| id|name |" + "\n" +
"+----+-----------+" + "\n" +
"|1024|dengqinghua|" + "\n" +
"+----+-----------+"
));
}
}
4.1.2 为什么使用内存数据库
SQL即表示数据计算、数据本身、又表示数据的迁移、存储、数据的访问, 是高度的抽象,是命令式的语言。 ---- 亚历山大 K Liu
角标非常重要的特色就是, 她存在非常多的"特殊规则", 而特殊规则的组成, 其实就是一条SQL拼接的过程. 如果使用内存数据库, 我们可以很方便地对角标进行管理和配置
回到上面说的例子:
我想要打一个超级男装单件优惠标, 标的定义如下: (商品是秒杀 而且 分类是男装) 或者 (商品为单件优惠 而且 剩余库存 在 10 到 20 之间)
如果我们以角标来看所有数据, 假设有一张角标视图表(badge_views), 她存储了所有的数据, 那么结合上述的DSL设计, 我们可以将上述需求转化为一条SQL:
SELECT
*
FROM
badge_views
WHERE
(isMiaosha = 1 AND inputTag = '男装')
OR
(isSingeSale =1 AND rangeStock BETEEN (10, 20))
从上面可以看到, 使用SQL的好处
- SQL里面的字段, 可将需求方的需求范围划分边界, 所有的需求都需要被审核, 必须是
条件集的一部分 - 所有的规则组成的SQL是所见即所得的, 排查bug非常方便
- SQL只是一种表达方式, 对应的存储介质可以是 MySQL, SQLlite, 内存数据库 或 任何一种可以解析SQL的存储引擎
最终我们考虑, 选择了内存数据库.
- 内存数据库速度很快(响应时间在0.01ms左右), 适合前端请求的实时查询
- 内存数据库可以执行SQL
4.2 角标计算设计
下面描述一个请求过来, 角标的匹配过程
![]()
下面通过这个例子, 描述一下角标匹配的完整过程
我想要打一个超级男装单件优惠标, 标的定义如下: (商品是秒杀 而且 分类是男装) 或者 (商品为单件优惠 而且 剩余库存 在 10 到 20 之间), 该角标只给男用户展示, 新老用户都可以看到, 所有页面都生效, 来源只作用于PC端
4.2.1 角标数据准备和过滤
首先需要创建一个角标
角标id 2 角标文案 超级男装单件优惠标 角标图片 XXX图片 开始时间 1月1日 结束时间 1月5日
基础规则
基础规则 1. 客户端类型 client_type: PC 2. 命中的页面 page_lists: 所有页面 3. 新老用户 user_type: 所有用户 4. 用户角色 user_role: 男用户
特殊规则
SELECT
*
FROM
badge_views
WHERE
(isMiaosha = 1 AND inputTag = '男装')
OR
(isSingeSale =1 AND rangeStock BETEEN (10, 20))
前端在请求角标数据时, 会获取到所有的角标, 假设现在按照规则权重由高到低排序之后, 有下面三个角标
角标1 用户角色: 女 角标2 超级男装单件优惠标 角标3 用户角色: 男
其中 角标1 被过滤调了, 只剩下角标2, 3
![]()
4.2.2 角标匹配数据准备
角标匹配数据是指 查看一个商品是否命中角标需要的数据, 如 一个角标的规则为: 商品库存 > 10. 那么 角标匹配数据则为: 商品库存
分析角标的特殊规则
SELECT
*
FROM
badge_views
WHERE
(isMiaosha = 1 AND inputTag = '男装')
OR
(isSingeSale = 1 AND rangeStock BETEEN (10, 20))
可以知道, 涉及到的字段包括
- isMiaosha
- inputTag
- isSingeSale
- rangeStock
这四个字段是从角标的视角来看的, 真实的业务系统的存储并没有 isMiaosha, inputTag 没有这些, 那到底要准备哪些字段呢? 故我们需要有一个映射配置
<SqlAnalyzer>
<!--是否为秒杀活动-->
<Entry>
<field>isMiaosha</field>
<type>boolean</type>
<sql>
<!--真实业务系统中的数据结构-->
SELECT 1 FROM products WHERE isSeckill = 1
</sql>
</Entry>
<!--分类名称-->
<Entry>
<field>inputTag</field>
<type>input</type>
<sql>
SELECT products.tagName FROM products
</sql>
</Entry>
<!--是否单件优惠-->
<Entry>
<field>isSingeSale</field>
<type>boolean</type>
<sql>
SELECT 1 FROM discountProducts WHERE discounts.conditionPurchaseCount = 1
</sql>
</Entry>
<!--库存范围-->
<Entry>
<field>rangeStock</field>
<type>range</type>
<sql>
SELECT product_stocks.count FROM product_stocks
</sql>
</Entry>
</SqlAnalyzer>
从配置关系表可以知道, 我们将会建立一些内存数据模型和对应的数据
-
products
public class Product { public int isSeckill; public String tagName; } -
discount_products
public class DiscountProduct { public int conditionPurchaseCount; } -
product_stocks
public class productStock { public int count; }
假设当前的商品的信息数据为
isSeckill: 1, tagName: "男装" conditionPurchaseCount: 1 count: 15
![]()
4.2.3 角标视图数据准备
角标匹配数据准备好之后, 便可以开始计算了
我们最终是希望执行这一条SQL
SELECT
*
FROM
badge_views
WHERE
(isMiaosha = 1 AND inputTag = '男装')
OR
(isSingeSale = 1 AND rangeStock BETEEN (10, 20))
这个就是角标视图的sql
为什么叫做角标视图? 因为角标所需要的数据, 和真实系统存在的数据是不一样的, 比如角标的 是否是秒杀 isMiaosha 字段, 在真实业务系统是不存在的, 而这个字段其实是一个SQL的Map: isMiaosha => SELECT 1 FROM products WHERE isSeckill = 1, 我们称之为视图.
所以我们会建立一个角标的数据库
public class BadgeView {
public int isMiaosha,
isSingeSale,
rangeStock;
public String inputTag;
}
而每一个字段都对应着一条SQL
| 字段名 | 对应的SQL | SQL执行的结果 |
|---|---|---|
| isMiaosha | SELECT 1 FROM products WHERE isSeckill = 1 | 1 |
| isSingeSale | SELECT 1 FROM discountProducts WHERE discounts.conditionPurchaseCount = 1 | 1 |
| rangeStock | SELECT product_stocks.count FROM product_stocks | 15 |
| inputTag | SELECT products.tagName FROM products | "男装" |
故我们得到了一个 BadgeView 的一条内存数据库数据
badgeView = new BadgeView(); badgeView.isMiaosha = 1 badgeView.isSingeSale = 1 badgeView.rangeStock = 15 badgeView.inputTag = "男装"
![]()
4.2.4 执行角标视图SQL
执行SQL
SELECT
*
FROM
badge_views
WHERE
(isMiaosha = 1 AND inputTag = '男装')
OR
(isSingeSale = 1 AND rangeStock BETEEN (10, 20))
可以发现, 执行出来是有结果的, 所以命中角标
![]()
整个过程如下:
![]()
5 角标查询优化
角标查询由原来前端计算 迁移 到了一个统一的服务, 供前端来调用. 所以各方对响应时间有着非常高的要求. 在不做优化的时候, 一个商品的角标匹配需要200ms左右, 这个是远远达不到响应时间要求的(5ms以内), 最终经过了优化之后, 角标匹配的时间稳定在1ms左右.
5.1 算法复杂度分析
假设 条件集合的总数为 N, 过滤后的角标数为 M, 单条SQL的执行时间为 S
则最坏情况下的时间复杂度为 O(M * N * S)
我们的时间优化主要放在
单条SQL的执行时间
这一点上
5.2 SQL执行优化
5.3 Connection Pool
在什么是内存数据库这一节中, 我们有一个测试
public class SqlRunnerTest {
static Database database;
static SqlRunner sqlRunner;
static String sql;
@Test public void run() throws Exception {
sqlRunner = new SqlRunner("merchant_system", database);
sql = "SELECT \n"
+ "\"products\".\"id\", \"sellers\".\"name\" \n"
+ "FROM \"merchant_system\".\"products\" \n"
+ "INNER JOIN \"merchant_system\".\"sellers\" \n"
+ "ON \"merchant_system\".\"sellers\".\"id\" = \"merchant_system\".\"products\".\"sellerId\" \n"
+ "WHERE \"sellers\".\"name\" = 'dengqinghua'";
Result<Record> result = sqlRunner.run(sql);
assertThat(result.format(), is(
"+----+-----------+" + "\n" +
"| id|name |" + "\n" +
"+----+-----------+" + "\n" +
"|1024|dengqinghua|" + "\n" +
"+----+-----------+"
));
}
}
您可以下载源码 run 一下该部分的测试, 可以发现这个测试非常慢
mvn test -Dtest=SqlRunnerTest [INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 4.23 s - in com.dengqinghua.calcite.SqlRunnerTest
一个非常简单的测试, 需要 4.23 s!, 这是完全不能接受的
经过分析得知, 主要的时间是在
public class SqlRunner {
private CalciteConnection initConnection() {
try {
Connection connection = DriverManager.getConnection("jdbc:calcite:", new Properties());
return connection.unwrap(CalciteConnection.class);
} catch (Exception ex) {
ex.printStackTrace();
throw new RuntimeException();
}
}
}
测试代码中, 每一次查询都是重新创建一个新的连接. 创建连接是非常耗时的. 最终, 我们选择使用了 connection_pool, 在项目启动的时候, 预生成一些连接
static final int POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2 + 1;
static Connection[POOL_SIZE] connectionPools;
static {
IntStream.range(0, POOL_SIZE).forEach(i -> {
connectionPools[i] = createConnection;
})
}
每次执行sql的时候, connection 直接从 connectionPools 中获取, 这样就可以直接优化创建连接的时间
5.3.1 Prepare Statement
我们发现在使用 SQL 查询的时候, 第一次查询非常慢, 但是反复执行多次之后, 之后的查询就很快了, 查看源码发现, calcite 使用了 jdbc 的接口. 而 jdbc 有 prepare Statement 的功能.
所以我们在执行SQL之前, 可以提前对SQL进行prepare
public class PreparedStatement {
public static void prepare(String[] sqls) {
for(sql : sqls) {
// 在项目启动的时候, 就执行一下所有可能的sql
prepare(sql);
}
}
}
5.3.2 NoneMatcher
我们在做了 connection_pool 和 preare statement 优化之后, 性能已经有了很大的提升, 但是还是有优化空间
考虑一个简单的角标视图的SQL:
SELECT
*
FROM
badge_views
WHERE
isMiaosha = 1
AND
inputTag = '男装'
AND
isSingeSale = 1
AND
rangeStock BETEEN (10, 20)
涉及到的字段和查询
| 字段名 | 对应的SQL |
|---|---|
| isMiaosha | SELECT 1 FROM products WHERE isSeckill = 1 |
| isSingeSale | SELECT 1 FROM discountProducts WHERE discounts.conditionPurchaseCount = 1 |
| rangeStock | SELECT product_stocks.count FROM product_stocks |
| inputTag | SELECT products.tagName FROM products |
可以看到, 为了执行 badge_views 对应的SQL, 必须要先执行上面的4条sql, 才能构造出一个 badgeView 的对象. 那么这个是不是必须的呢?
其实分析语义的时候我们发现
- isMiaosha
- inputTag
- isSingeSale
- rangeStock
这几个值只有有一个不满足条件, 其实下面的SQL就没有不要再执行了
| 字段名 | 对应的SQL | SQL执行的结果 |
|---|---|---|
| isMiaosha | SELECT 1 FROM products WHERE isSeckill = 1 | 0 |
| isSingeSale | 无需计算 | |
| rangeStock | 无需计算 | |
| inputTag | 无需计算 |
假如 isMiaosha 的结果为 0 了, 其实没有必要往下面再执行了, 直接返回即可.
所以我们提出了 NoneMatcher 的概念
如果我执行一条sql, 发现这条sql的值和预期的值不一致, 则直接返回(not match成功, 剩下的sql不需要执行了), 如果是一致, 则继续往下执行
这样99%的角标匹配规则都非常快, 而且将原来的 O(M) 的复杂度直接变成了 O(1)
5.3.3 SQL自动转化为java代码
To make something easier or safer to use, create an abstraction layer. To make something faster, remove one or more abstraction layers.
SQL即是高度抽象的语言, 但是为了执行SQL, SQL内存引擎会生成对应的代码, 检测SQL的正确性, 字段存在性等一系列操作. 这些抽象会使得本来一个很简单的操作变得很慢.
如下面的例子:
| 字段名 | 对应的SQL | SQL执行的结果 |
|---|---|---|
| isMiaosha | SELECT 1 FROM products WHERE isSeckill = 1 | 0 |
如果我们已经有了products对象, 直接取 product.isSeckill 即可获取到数据
public class Product {
public int isSeckill;
public String tagName;
}
进一步的优化为:
| 字段名 | 对应的SQL | 对应的java代码 |
|---|---|---|
| isMiaosha | SELECT 1 FROM products WHERE isSeckill = 1 | product.isSeckill == 1 ? 1 : 0 |
经过测试发现, 执行java原生的代码的时间, 大约为 单条sql 的100 倍
所以我们分析了一些命中率非常高的 条件, 将这些条件转化为 java 原生代码, 再使用 NoneMatcher 进行匹配, 最终角标的整体的响应时间在 1ms 左右
5.4 优化总结
- connectionPool, 项目启动时创建连接
- PreparedStatement, 项目启动时将所有sql执行一遍
- NoneMatcher, 分析sql语义, 存在一个不满足条件的, 剩下的sql不再执行
- 将一些简单的sql转化为java代码
6 总结
角标系统的例子是SQL型数据处理的一个非常常见的例子, 她的整体思路为
源数据 -> 视图数据 -> 源数据 -> 视图数据 -> ...
也就是说将不同的数据组合, 组合完之后变成一个视图, 该视图又是下一个数据视图的源数据
源数据 到 视图数据, 是通过 SQL 这个通用语句来表达的.
但是使用该方式也有一些缺点, 下面分别分情况进行表述.
6.1 SQL的缺点
6.1.1 SQL爆炸
有时候源数据 -> 视图数据是很复杂的, 即SQL中包含很多语句, 包括 INNER JOIN, UNION, CASE, WHEN 等等, 这样的SQL是非常不可读的, 而且很难进行维护
如下面的SQL:
SELECT
ROUND(COALESCE(MIN(p), 0)/100.0, 2)
FROM (
SELECT
CAST(discountRules.price - discountRules.savedAmount AS DECIMAL(10, 2))
AS p
FROM
input_view.discountRules
WHERE
(discountRules.price >= discountRules.conditionMoney AND discountRules.type = 0 AND discountRules.conditionMoney > 0)
OR
(discountRules.conditionPurchaseCount = 1 AND discountRules.type = 1)
UNION
SELECT
CAST((discountRules.price) * (1 - discountRules.savedPercent/10000.0) AS DECIMAL(10, 2))
AS p
FROM
input_view.discountRules
WHERE
(discountRules.price >= discountRules.conditionMoney AND discountRules.type = 0 AND discountRules.conditionMoney > 0)
OR
(discountRules.conditionPurchaseCount = 1 AND discountRules.type = 1)
UNION
SELECT
CAST((discountRules.price - COALESCE(discountRules.price/NULLIF(input_view.discountRules.conditionMoney, 0), 0) * discountRules.noLimit * discountRules.savedAmount) AS DECIMAL(10, 2))
AS p
FROM
input_view.discountRules
WHERE
(discountRules.price >= discountRules.conditionMoney AND discountRules.type = 0 AND discountRules.conditionMoney > 0)
OR
(discountRules.conditionPurchaseCount = 1 AND discountRules.type = 1)
) t
看到人大都是在心里说WTF. 像上面的例子就是一个SQL爆炸的case.
SQL不应过多的进行数据地处理流程, 而是简单的查询和组合等操作.
数据的处理应该是提供对应的操作算子或者函数, 在 spark sql在喜马拉雅的使用之xql 这篇文章中就实现了操作算子: load 和 save 等.
操作算子的实现比较复杂, 而角标系统只有这一个复杂的SQL爆炸case, 所以角标系统并未对此做扩展.
6.1.2 SQL测试困难
SQL如何进行unit test? 修改了之后如何保证修改的逻辑是对的?
角标系统将原有的业务代码大都浓缩到了SQL中, 这使得原来便于测试的业务代码变得困难. 在当前的角标系统中, 我写了一个test, 仅仅检测SQL的语法, 而不检查SQL本身的业务含义.
/**
* 防止SQL写得不对, 导致直接报错, 所以在这里会跑这个测试
*
* <p>
* 在上线之前务必执行
*
* <pre>
* mvn -Dtest="SqlAnalyzerTest#testEverySQLRunnable" test
* </pre>
*
* @throws Exception 如果SQL写得不对, 在这儿测试这儿会报错
*/
@Test public void testEverySQLRunnable() throws Exception {
// 这个地方设置了如果执行SQL报错, 就会抛出异常
Helper.setPrivateStaticField(SqlRunner.class, "isThrowExceptionWhenRunSqlFailed", true);
Field field = SqlRunner.class.getDeclaredField("PREPARE_VIEWS");
field.setAccessible(true);
SchemaView[] prepareViews = (SchemaView[]) field.get(SqlRunner.class);
for (SchemaView bean : prepareViews) {
List<String> sqlList = bean.allPossibleSqls();
// 执行所有SQL
sqlList.forEach(sql -> SqlRunner.run(bean, sql));
}
}
6.2 总体评价
虽然SQL存在上述问题, 但是总的来说, 角标解决了原有的问题, 缩短了角标的实现时间, 添加一个角标只需要在后台配置, APP, PC端和数据层都不需要做任何更改. 另外, SQL本身的自解释性很强, 数据的流转也很清晰, 出了问题也很好排查, 是一次非常不错的优化.
